




如何在代理服务器中配置网络爬虫
将NetNut代理服务器与Web Scraper Chrome浏览器扩展(网页爬虫工具)集成,用户可通过可靠匿名的数据采集提升网页抓取能力。本指南将详解如何在Web Scraper中配置代理服务器,确保高效安全抓取数据。
什么是谷歌浏览器爬虫插件
Web Scraper(Chrome浏览器扩展)是专业的网站数据提取工具,支持用户:
• 创建站点地图(sitemap)定义目标网站结构与数据字段;
• 自动化采集数据,无需手动操作即可获取海量网络信息;
• 抓取动态内容、处理分页数据、导出多格式结果,让开发者、研究人员与数据分析师高效收集网络数据,堪称行业必备工具。
如何在网络爬虫中配置代理
准备工作:
1. 1. 在Chrome应用商店安装 Web Scraper 浏览器扩展;
2. 注册 Web Scraper Cloud 账号
3. Subscribe to Scale plan.
创建自定义代理服务器:
1. 1. 登录Web Scraper云端版账户;
2. 左侧工具栏选择代理管理器(Proxy Manager)

3. 下拉菜单中选择NetNut.cn 动态住宅代理”

4. 填写配置信息:自定义名称、用户名、密码,并选择区域;
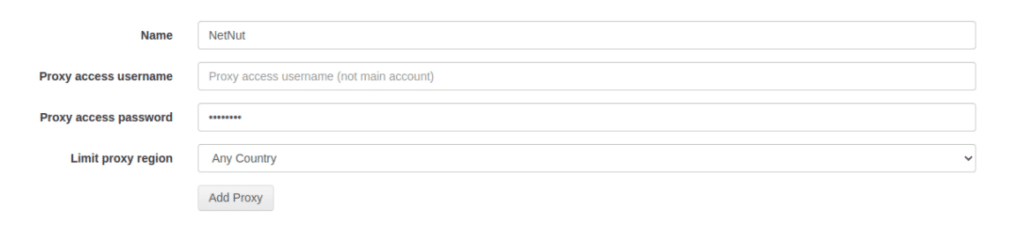
5. 点击添加代理服务器(Add Proxy)。
将NetNut与Web Scraper集成:
1. 从左侧工具栏进入“My Sitemaps”。
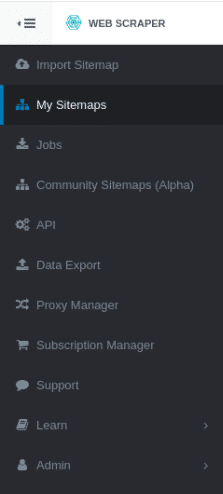
2.找到目标站点地图,点击 “Details page”;
3.在Proxy下拉菜单中选择自定义代理名称;
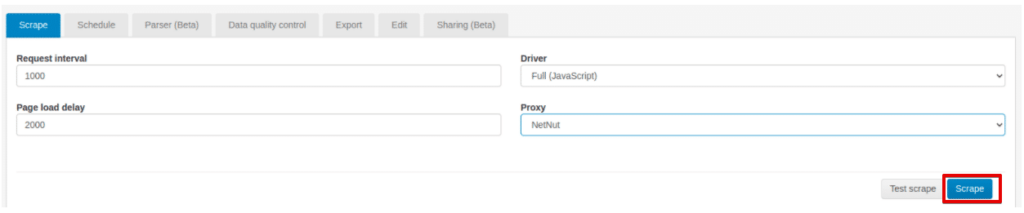
4. Click “Scrape”.
配置完成!网络爬虫Web Scraper云端版将通过 NetNut代理服务器
执行抓取任务。
Share


