



代理在人工智能数据标记和注释中的作用
每个高性能 AI 模型的背后都有大量标记数据。无论是识别图像中的对象、了解推文中的客户情绪,还是跨语言翻译文本,人工智能标签都可以将原始数据转化为机器学习算法的结构化训练燃料。
然而,虽然注释工具和标记策略受到了很多关注,但最容易被忽视但最关键的组件之一是首先如何收集数据。在许多情况下,这意味着从网络中提取真实世界的高上下文内容,通常来自特定区域或内容敏感的网站。
这就是 NetNut 发挥关键作用的地方。作为住宅代理和移动代理的提供商,NetNut 帮助人工智能团队以合乎道德的方式访问全球数据,避免 IP 封锁,并在不同行业和地区扩展其值得标记的内容集合。在本指南中,我们将分解完整的人工智能标签管道,并探讨代理如何实现更智能、更快、更多样化的注释工作流程。
什么是人工智能标签,为什么它很重要?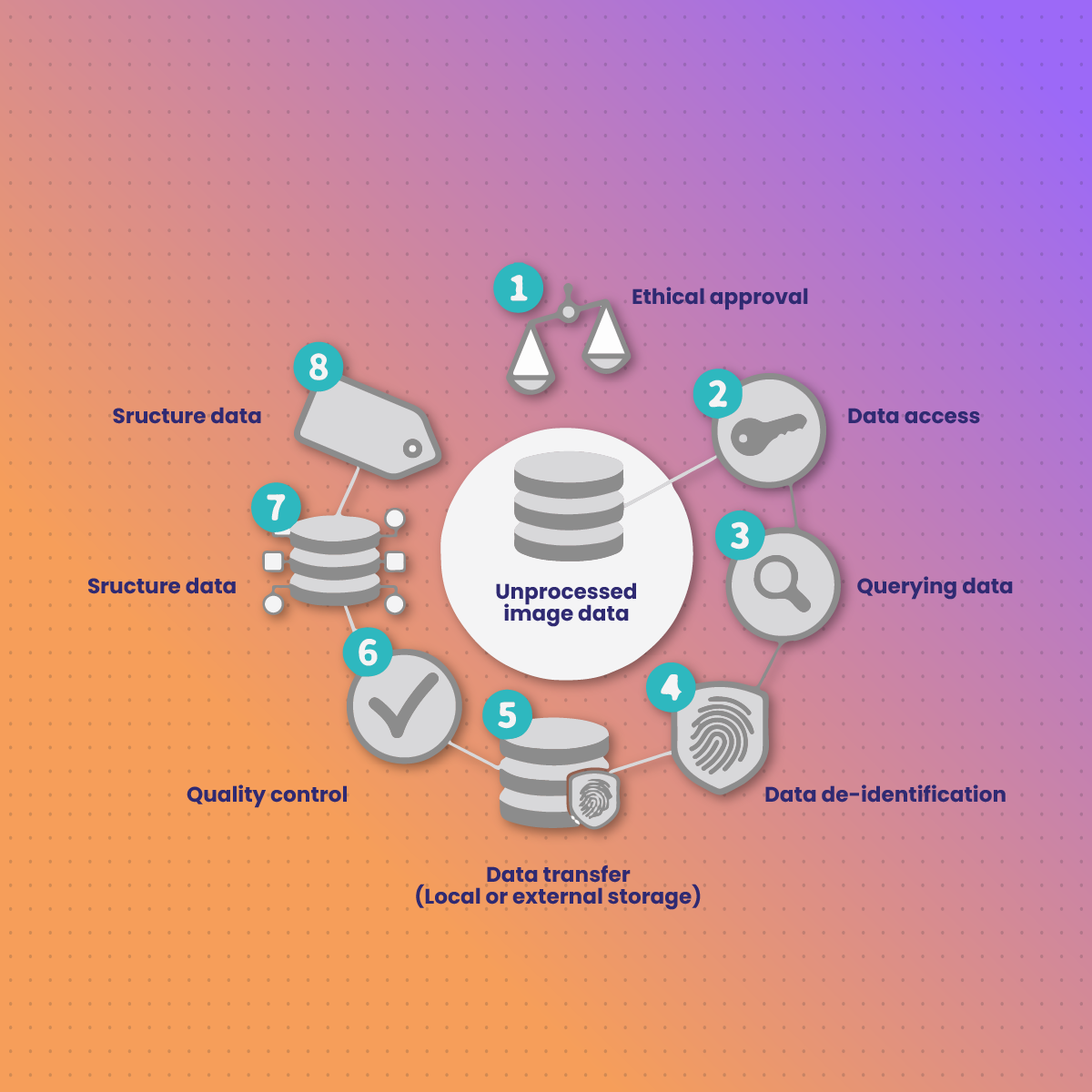
AI 标记(也称为数据注释)是向原始数据添加有意义的元数据的过程,以便可用于训练监督机器学习模型。标签帮助人工智能模型了解它们正在查看或收听的内容,从而使它们能够做出准确的预测或分类。
常见 AI 标注任务示例:
- 图片分类:在照片中标记猫与狗
- 对象检测:在交通镜头中围绕车辆绘制边界框
- 文本分类:将电子邮件标记为垃圾邮件或非垃圾邮件
- 情绪分析:将社交媒体帖子标记为积极、消极或中性
- 命名实体识别 (NER):突出显示文本中的名称、组织或日期
对于人工智能的准确性来说,高质量的标签是不容谈判的。不一致、有偏见或不相关的标签可能会降低模型性能,导致预测不可靠,甚至生产中的道德问题。
但是,在标记任何内容之前,您需要获取正确的数据。如果您正在训练聊天机器人来理解不同方言的俚语,或者训练为区域买家量身定制的产品推荐系统,您的数据集必须反映这些细微差别。这意味着收集相关示例,这就是代理变得至关重要的地方。
人工智能数据标记的挑战
虽然标签本身是一个资源密集型过程,但在标签开始之前就会出现最大的障碍之一:收集高质量的数据。
人工智能标签管道中的主要挑战:
- 利基领域的数据稀缺:医疗保健、法律或金融等行业需要特定的数据类型,这些数据类型通常存在付费墙、登录或区域限制。
- 来自有限来源的偏见:依赖一些通用数据集可能会产生扭曲的结果,尤其是在基于语言的人工智能模型中。
- 地理限制:许多网站根据用户位置提供不同的内容。如果无法轮换 IP 或访问特定区域的内容,宝贵的训练数据仍然遥不可及。
- IP 块和速率限制:抓取大量数据(尤其是对于实时用例)可能会导致服务器端禁令或验证码墙。
- 注释成本和速度:人工标记速度慢且成本高昂。您的原始数据越有针对性和预清理性,您的注释工作流程就会变得越快。
解决方案:这就是 NetNut 的代理网络发挥作用的地方。通过访问 150+ 个国家/地区的住宅 IP,NetNut 允许数据团队绕过内容限制,收集新鲜、多样化的内容以进行 AI 训练和标记——合乎道德且高效。
代理适合 AI 标签管道的位置
在训练 AI 模型和标记数据集之前,有一个关键步骤:数据采集。无论您是获取产品评论、论坛帖子、职位描述还是医学摘要,此步骤都决定了整个数据集的质量、相关性和完整性。
代理在这里发挥着关键作用,它能够实现对网站的可靠、不可检测的大规模访问。如果没有它们,数据工程师就有可能遇到 IP 封锁、面临特定区域的限制或获得不完整的内容。
代理如何支持人工智能标签生命周期:
- 大规模数据收集:代理允许在不触发服务器禁令的情况下进行大量抓取。
- 地理本地化内容:住宅和移动代理可让您从特定国家或语言收集数据,从而增强数据集的多样性。
- 绕过机器人检测:轮换代理有助于避免验证码和 IP 禁令,确保不间断的抓取。
- 会话稳定性:粘性会话允许跨多步骤抓取(例如,分页的职位发布或受登录保护的内容)进行一致的访问。
NetNut 优势:
与公共代理或不可靠的 VPN 不同,NetNut 的代理网络专为企业级数据提取而构建。NetNut 在真实住宅和移动设备上拥有数百万个 IP,使 AI 团队能够构建更好的训练数据集,而不会影响道德、速度或可靠性。
使用特定区域的内容丰富 AI 数据标签
上下文在人工智能中很重要。仅根据北美的英语评论进行训练的模型可能会误解亚洲或欧洲的俚语、语气或产品偏好。为了构建全球准确的模型,团队需要特定于区域的数据。
代理允许您模拟世界任何地方的本地用户,从而收集反映区域语言、规范、趋势甚至法律要求的数据,从而实现这一点。
为什么地理定位内容可以增强人工智能标签:
- 语言多样性:访问母语或方言的数据,提高 NLP 性能。
- 文化相关性:捕捉影响标签准确性的习语、行为模式和社会背景。
- 合规性驱动的人工智能:对于金融、法律或医疗保健行业,本地数据可确保您的模型符合特定国家/地区的要求。
NetNut 的地理定位代理可以为 AI 构建多语言和文化敏感的数据集。从抓取德国科技职位列表到收集西班牙电子商务评论,NetNut 大规模提供本地化内容,这对于准确的数据标记至关重要。
标签数据收集中的道德考虑
数据越大,责任越大。随着人工智能系统在社会中的影响力越来越大,数据收集和标记的道德规范比以往任何时候都更加重要。
人工智能数据收集的关键道德准则: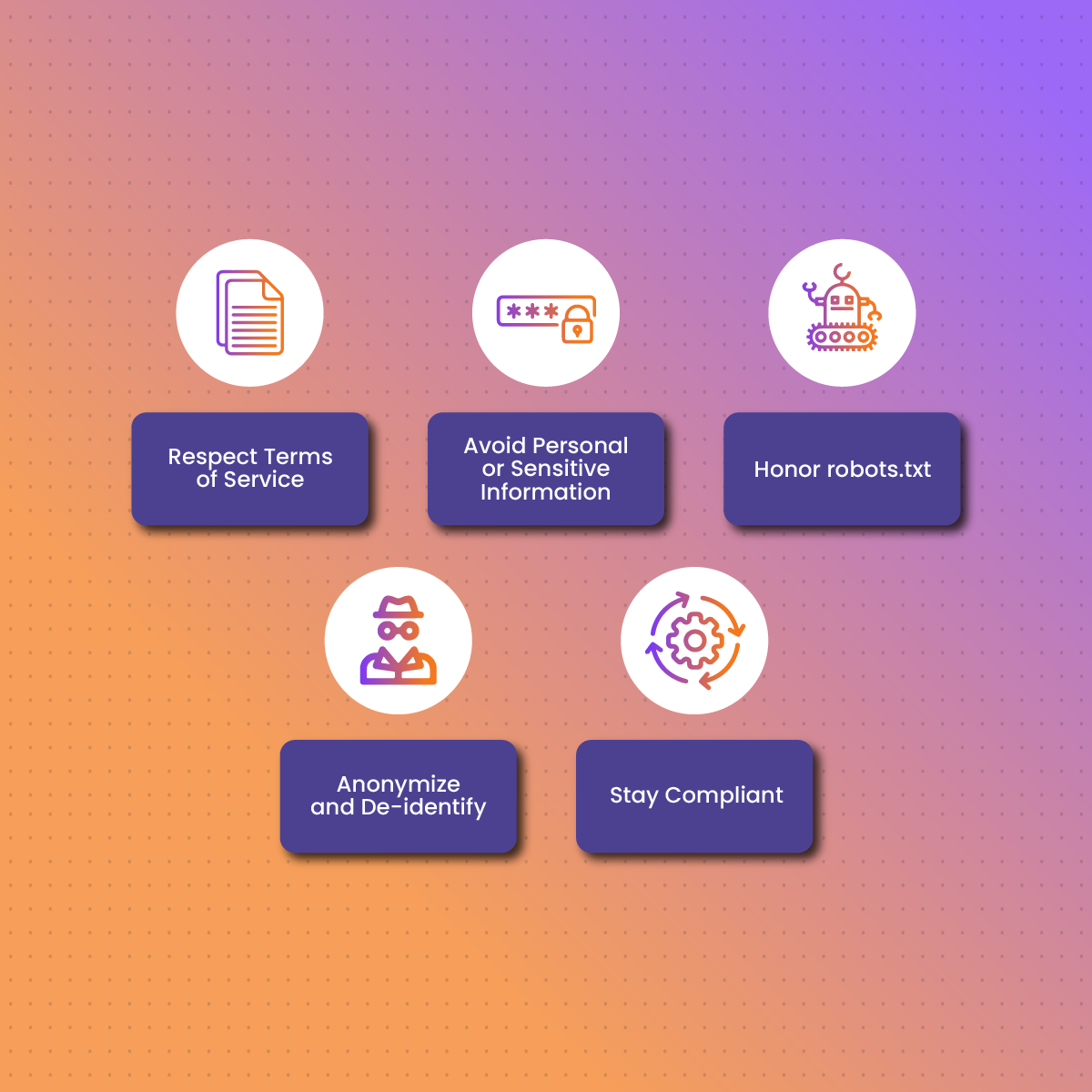
- 尊重服务条款:不要抓取明显受限或付费墙后面的内容。
- 避免个人信息或敏感信息:仅收集面向公众的匿名数据。
- 尊重 robots.txt:在适用的情况下,请遵循网站抓取指南。
- 匿名化和去标识化:在标记之前从训练数据中删除姓名、电子邮件和个人标识符。
- 保持合规:在收集和使用用户生成的内容时,请遵守 GDPR 和 CCPA 等隐私法。
NetNut 的基础设施通过帮助团队:
- 遵守速率限制并避免主动爬网
- 轮换 IP 以减少服务器负载和检测
- 仅关注公开的、合法可访问的内容
道德人工智能始于道德数据收集,而像 NetNut 这样的代理在这一基础上发挥着关键作用。
通过代理自动化扩展 AI 标签工作流程
随着人工智能模型变得更加专业化,对不断更新、标记数据集的需求也在增长。手动数据收集和注释根本无法跟上现代人工智能工作流程的步伐。答案是什么?由代理提供支持的自动化.
代理自动化如何支持可扩展的 AI 标签:
- 不会中断的数据管道:代理可确保跨时区和地理位置稳定、不间断地访问内容。
- 实时内容刷新:定期从动态来源(例如新闻、论坛、招聘委员会)抓取可保持数据集的相关性。
- 代理轮换:自动循环浏览住宅 IP,规避 IP 封禁,降低指纹风险。
- 会话管理:粘性会话有助于收集分页或登录门控数据以进行结构化标记。
通过将抓取框架(如 Scrapy、Puppeteer 或 Playwright)与 NetNut 的代理 API 相结合,人工智能团队可以自动化大规模、区域不同的数据收集管道,这些管道直接馈送到注释工具中,从而创建从原始 Web 内容到标记训练集的无摩擦标记工作流程。
NetNut 的实际应用:无论您是构建仇恨言论分类器、医学知识助手还是多语言搜索引擎,NetNut 的代理都可以让您自由地在全球范围内扩展数据标记管道,而无需违反规则或碰壁。




